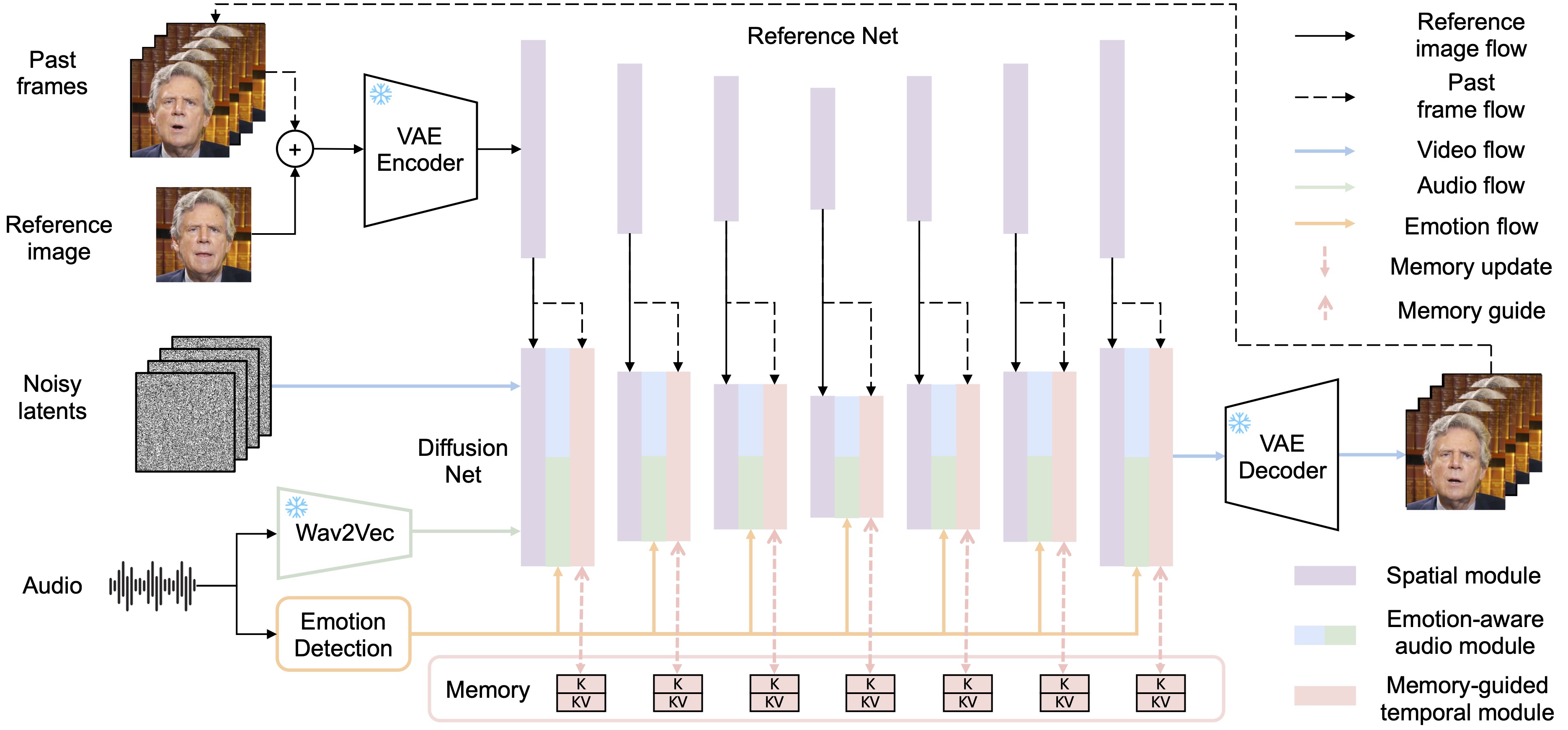
Our work is made possible thanks to high-quality open-source talking video datasets (including HDTF, VFHQ, CelebV-HQ, MultiTalk, and MEAD) and some pioneering works (such as EMO and Hallo).
We acknowledge the potential of AI in generating talking videos, with applications spanning education, virtual assistants, and entertainment. However, we are equally aware of the ethical, legal, and societal challenges that misuse of this technology could pose. To reduce potential risks, we have only open-sourced a preview model for research purposes only. Demos on our website use publicly available materials. We welcome copyright concerns—please contact us if needed, and we will address issues promptly. Users are required to ensure that their actions align with legal regulations, cultural norms, and ethical standards. It is strictly prohibited to use the model for creating malicious, misleading, defamatory, or privacy-infringing content, such as deepfake videos for political misinformation, impersonation, harassment, or fraud. We strongly encourage users to review generated content carefully, ensuring it meets ethical guidelines and respects the rights of all parties involved. Users must also ensure that their inputs (e.g., audio and reference images) and outputs are used with proper authorization. Unauthorized use of third-party intellectual property is strictly forbidden. While users may claim ownership of content generated by the model, they must ensure compliance with copyright laws, particularly when involving public figures' likeness, voice, or other aspects protected under personality rights.
Citation
@article{zheng2024memo,
title={MEMO: Memory-Guided Diffusion for Expressive Talking Video Generation},
author={Zheng, Longtao and Zhang, Yifan and Guo, Hanzhong and Pan, Jiachun and Tan, Zhenxiong and Lu, Jiahao and Tang, Chuanxin and An, Bo and Yan, Shuicheng},
journal={arXiv preprint arXiv:2412.04448},
year={2024}
}